






Sistemas e Aplicações Hipermédia

Tema: Modelos de desenvolvimento de aplicações hipermédia para a Web
II - Segunda parte de uma série de cinco.Contexto
Na primeira parte deste documento apresentou-se de forma geral a arquitectura multi-nível das aplicações baseadas na tecnologia World Wide Web. A esta classe de aplicações designa-se, neste documento, de Sistemas de Informação Hipermédia para a Web (SIHW).
A segunda parte do documento apresenta, com detalhe, as características envolvidas na construção de SIHW utilizando o mecanismo CGI1. Assume-se que o leitor tenha conhecimentos básicos sobre as principais componentes da tecnologia WWW, nomeadamente: a linguagem de definição de páginas (HTML2) - e especificamente a utilização do elemento FORM3 -, o conceito de URL4, e o funcionamento do protocolo HTTP5.
Parte 2: Soluções baseadas no Common Gateway Interface.
II-1. Motivação.
A especificação CGI foi concebida e implementada originalmente no servidor Httpd do NCSA em 1994 como necessidade de estender a sua funcionalidade de forma flexível e escalável. O objectivo foi que o servidor Web providenciasse um interface simples que outros quaisquer processos servidores pudessem interactuar de forma independente. Deste modo conseguiu-se responder a pressões de introdução no servidor Web de novas funcionalidades (e.g. acesso a sistemas de bases de dados específicas, conversores de dados, etc.) de uma forma elegante e flexível: apenas providenciando um interface ao nível de comunicação entre processos.
Segundo o CGI surgiram as primeiras experiências de extensão das funcionalidades encontradas nos servidores Web. Os primeiros sistemas consistiram essencialmente na conversão de diferentes protocolos e formatos de informação (e.g. X.500, WAIS, etc.) para interfaces HTML. Por esta razão é habitual designarem-se ao SIHW baseados no CGI de “gateways” (conversores). Também são denominados de “scripts” pelo facto de serem historicamente desenvolvidos com linguagens de programação interpretadas (e.g. PERL, TCL).
II-2. Modelo geral de funcionamento.
Um SIHW executa um conjunto de processamentos específicos e vai gerando dinamicamente uma sequência de páginas HTML à medida que interactua com o utilizador (através de um cliente, ou browser, Web). Contudo, a questão inicial que se coloca a quem pretende desenvolver um SIHW é a seguinte: Como é que o servidor Web sabe que a página (referenciada por determinado URL) solicitada pelo cliente corresponde ao resultado da execução de determinado processo e não a um acesso directo ao sistema de ficheiros? A solução a esta questão encontra-se na possibilidade de configuração do servidor.
Os servidores Web têm um conjunto de ficheiros de configuração, os quais apresentam um conjunto de directivas de forma a controlar o seu modo de funcionamento, controlar os acessos de utilizadores, etc. De entre esse conjunto, existe uma directiva que permite indicar se determinado URL corresponde à execução de um processo CGI. Por exemplo, nos servidores do CERN (ou baseados neste) utiliza-se a directiva “Exec /directoria-virtual/* /directoria-real/*”, enquanto nos servidores do NCSA (ou baseados neste) utiliza-se a directiva “ScriptAlias /directoria-virtual/ /directoria-real/”. Como exemplo, imagine-se o servidor do NCSA com a seguinte directiva “ScriptAlias /cgi-bin/ /bin/cgi-bin/”. O URL “/cgi-bin/cal” permitiria que fosse executado o script “cal” que deveria existir na directoria real “/bin/cgi-bin”, enquanto que o URL “/cgibin/cal” poderia corresponder ao retorno de uma mensagem de erro.
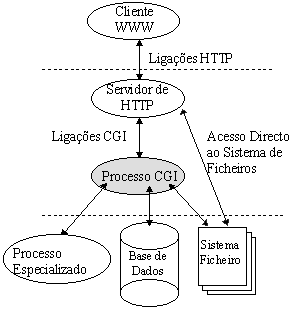
Figura 1: O modelo computacional de um SIHW baseado no CGI.
A figura 1 esquematiza o modelo computacional de um SIHW baseado no mecanismo CGI. Conceptualmente, em cada acesso desencadeado pelo cliente, o processo CGI evolui ao longo das seguintes fases:
- É criado/lançado pelo servidor de HTTP;
- Os dados (provenientes do servidor de HTTP) são recebidos através do “canal” CGI (e.g. em Unix, através de variáveis de ambiente e do standard input);
- Analisa os dados recebidos e verifica a sua validade;
- Executa determinado processamento dependendo da informação recebida;
- Produz resultados (geralmente no formato HTML) para o “canal” CGI (e.g. em Unix, é o standard output), que serão lidos pelo servidor HTTP e redireccionados para o cliente.
Como se constata o processo CGI é um processo de “vida curta”, ou seja tem um ciclo de vida bem determinado, mas apenas circunscrito ao período temporal de um acesso desencadeado pelo cliente. De seguida descreve-se os detalhes da informação que é recebida e enviada no “canal” CGI, cuja descodificação/codificação é essencial no desenvolvimento de SIHW.
II-3. Informação que é passada no “canal” CGI:
Do servidor Web para o processo CGI ...
A informação recebida pelo, que se designa de “canal” CGI distribui-se basicamente por três grupos:
- Informação contida no próprio URL;
- Informação específica do interface CGI; e
- Informação passada através de pares nome/valor de elementos HTML que façam parte do elemento FORM activado.
A figura 2 ilustra, com um exemplo, a informação genérica que é passada no URL. São passados ao processo CGI dois grupos de informação separados pelo caracter “?”: o path info e a query string. Ambos os grupos de informação são opcionais e independentes entre si. Em geral o path info é usado para indicar o path lógico de determinado recurso. Imagine-se que um SIHW com nome “word” que sabe tratar com determinados ficheiros, aos quais realizava determinada tarefa. Assim o URL “http://.../word.exe/teste.doc” lança a execução do processo “word.exe” e passa-lhe como argumento o documento “teste.doc” (que é o path info). A informação passada na query string consiste num conjunto de pares nome/valor separados pelo caracter “&”. A separação entre o nome e o valor de cada par é dada pelo caracter “=“. Os nomes e valores são codificados de modo que espaços em branco são substituídos pelo caracter “+” e outros caracteres não ASCII 7-bits são codificados em hexadecimal. Em geral, é da responsabilidade dos processos CGI descodificar a informação passada no URL.
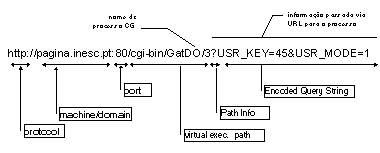
Figura 2: Informação genérica contida num URL.
Outro grupo de informação passada no “canal” CGI consiste em informação específica do protocolo HTTP e do próprio interface CGI. Exemplo dessa informação são os seguintes parâmetros:
- Request Protocol (indicação do protocolo, e versão, utilizado - e.g. “HTTP/1.0”);
- Request Method (indicação do protocolo invocado - e.g. “POST6”);
- Server Name (nome lógico da máquina do servidor - e.g. “xico”);
- Server Port (porto onde o servidor HTTP se encontra à escuta - e.g. “80”);
- CGI Version (versão do CGI - e.g. “CGI/1.1 WIN”);
- Remote Address (endereço IP da máquina do cliente - e.g. “146.196.0.114”);
- Content Type (indicação do tipo MIME7 dos dados - e.g. “application/x-www-form-urlencoded” - exclusivo de métodos POST);
- (outros ... consulte-se o manual do programador do servidor Web escolhido).
Por fim, o último grupo de informação passada também no “canal” CGI consiste em todos os pares nome/valor de todos os elementos activos (INPUT, SELECT e TEXTAREA, ...) que façam parte do elemento FORM seleccionado (ou activado). Esses pares também se encontram codificados (escaped) do mesmo modo que a informação passada na query string num URL. Toda a informação, mesmo os elementos INPUT do tipo hidden, são passados “em claro”, sem portanto passarem por qualquer processo de criptografia ou segurança.
Do processo CGI para o servidor Web ...
O processo CGI executa um conjunto de processamentos e por fim gera um resultado que é passado pelo servidor de HTTP para o cliente. Em geral o resultado é constituído por duas partes:
- O cabeçalho, que consiste em uma, ou mais, linhas de texto, e que é separado do corpo por uma linha em branco; e
- O corpo, que é um conjunto de informação no formato MIME, cujo tipo teve de ser especificado no cabeçalho.
Note-se que embora, em geral, o resultado de um processo CGI seja uma página HTML (tipo MIME: text/html), não é forçoso que assim seja.
O servidor HTML reconhece as seguintes linhas de cabeçalhos:
- Content-Type (determina o tipo MIME do corpo);
- Status (indica o código de resposta ao pedido; caso a resposta não contenha esta linha o servidor assume “operação com sucesso” e gera uma linha “status = 200 OK”);
- Location (permite fazer redirecção de outro documento)
- se o valor for uma referência a um ficheiro local, o servidor envia-o como resultado do pedido;
- caso contrário, o servidor retorna uma resposta “redirect” para o cliente pedir directamente o objecto pretendido.
O processo CGI tem ainda a possibilidade de enviar uma determinada resposta sem interferência do servidor. Nesse caso deverá iniciar a resposta com “HTTP/1.0”. O servidor apenas envia o resultado para o cliente sem qualquer análise do cabeçalho. É da responsabilidade do processo gerar um cabeçalho correcto.
II-4. Particularidades de Implementação do CGI ...
CGI em ambiente UNIX ...
Em ambiente UNIX o modelo CGI apresenta as seguintes particularidades:
- O servidor HTTP cria um seu filho (usando a chamada ao sistema fork()), HTTPD’, o qual irá lançar a execução (usando a chamada ao sistema exec()) o processo CGI;
- Entre os processos HTTPD’ e CGI, é partilhado os seus streams de input e de output assim como variáveis de ambiente;
- Assim o HTTPD’ passa parte da informação (designadamente os parâmetros específicos do CGI) por variáveis de ambiente, e outra (os pares nome/valor de campos de elementos FORMs) no standard input do processo.
- Por fim o processo escreve o resultado no seu standard output (standard input do HTTPD’) e termina; competindo ao HTTPD’ reenviar essa informação para o cliente.
- O HTTPD’ notifica o seu pai que terminou a sua execução.
Este é o mecanismo clássico dos servidores Web de 1Ş geração (e.g. servidor Web do NCSA ou do CERN). Actualmente os servidores Web de 2Ş geração (Microsoft Internet Information Server, Oracle WebServer, Netware WebServer, etc.) apresentam novas capacidades, tais como multithreading ou integração nativa com gestores de bases de dados, cuja descrição sai fora do âmbito da presente descrição.
CGI para ambiente Windows (Win-CGI) ...
O ambiente Windows (entenda-se Windows 3.x e Windows 95) não tem o mesmo mecanismo de comunicação e sincronização de processos existente em Unix. Foi adoptado (na implementação de servidores Web para Windows) um mecanismo bastante simples, baseado na leitura/escrita em ficheiros temporários e no mecanismo de notificação de mensagens existente (Win-CGI8). A figura 3 ilustra o esquema geral.
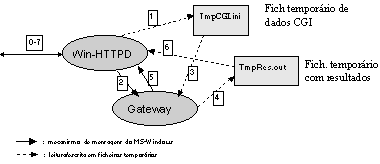
Figura 3: O CGI em ambiente MS-Windows (Win-CGI).
Na sequência de um pedido realizado por um cliente (0), o servidor cria o ficheiro temporário “tmpcgi.ini” (1) e eventualmente outros ficheiros temporários complementares que contêm toda a informação necessária a passar ao processo CGI. Seguidamente o servidor lança a execução do processo (2) indicando-lhe o path do ficheiro de informação CGI e o path do ficheiro onde espera que os resultados venham a ser escritos. O processo com base nessa informação, lê o conteúdo do ficheiro “tmpcgi.ini” (3), realiza os seus processamentos e escreve o resultado no ficheiro “tmpres.out” (4). Por fim notifica o servidor que termina (5). Este lê o conteúdo do ficheiro temporário “tmpres.out” (6), e envia uma resposta no formato HTTP ao cliente (7).
O ficheiro “tmpcgi.ini” é um ficheiro particular em Windows (profile), já que é um ficheiro de texto, mas cujo conteúdo encontra-se organizado em secções, e cada secção em entradas na forma “nome = valor”. Este ficheiro contém as seguintes secções:
- CGI, contém a informação essencial passada no CGI;
- Accept, contém os tipos MIME aceitáveis pelo cliente;
- System, contém items específicos da implementação CGI em Windows (designadamente Output file e Content File);
- Extra Headers, contém informação que foi introduzida, no pedido, pelo cliente, mas que não se encontra normalizada;
- Form Literal, esta secção é apenas geradas em resposta a pedidos POST, e corresponde aos pares nome/valor dos campos de um elemento FORM.
- Form External e Form Huge são secções complementares para tratarem de pares nome/valor com valores muito grande e/ou com caracteres de controlo (informação em binário).
O Win-CGI teve (tem!) a virtude de permitir o desenvolvimento de SIHWs para o ambiente computacional mais popular: MS-Windows. Deste modo tornou-se possível o desenvolvimento de protótipos de SIHWs sobre plataformas relativamente baratas e utilizando-se os principais ambientes de desenvolvimento aí existentes. Todavia, os SIHW baseados no Win-CGI apresentam um nível de desempenho bastante baixo devido aos mecanismos de comunicação e sincronização de processos utilizados.
II-5. Observações finais.
O CGI conjuntamente com o elemento FORM da linguagem HTML foi um dos primeiros e importantes passos no sentido da introdução da interactividade na Web. Permitiu a integração de inúmeros serviços, o acesso remoto a diferentes bases de dados e à informação mantida por um infinidade de sistemas legados.
O CGI é a definição de um interface independente da plataforma, do sistema operativo e da linguagem de programação, que permite estender a funcionalidade básica dos servidores Web.
Em ambientes Unix a generalidade dos processos CGI desenvolvidos têm sido baseados na linguagem PERL. Esta é uma linguagem interpretada, com uma sintaxe semelhante à linguagem C, de propósitos gerais e de alto nível. Foi originalmente usada como linguagem de criação de scripts para administração de sistema, utilizando funcionalidades de outras ferramentas Unix (shell, awk e sed), tais como funções poderosas de manipulação de texto. Outras soluções também adoptadas em ambiente Unix têm sido as linguagens C e C++.
Em ambientes Windows (Windows 95 e Windows NT) as ferramentas/ambientes utilizados são aqueles que o maior número de programadores já dominava, noutros contextos de desenvolvimento: Visual Basic, VC++, Delphi, PowerBuider, etc.
Embora o mecanismo CGI seja simples de entender, e fácil de adoptar em aplicações relativamente simples - como por exemplo conversores de dados -, apresenta um conjunto de dificuldades quando se desenvolve SIHW efectivamente complexos, com diferentes visões sobre um conjunto heterogéneo de informação, com diferentes níveis de segurança e diferentes tipos de utilizadores, etc. A manutenção do estado entre sucessivas gerações de páginas HTML, assim como o suporte à execução de transações complexas que envolvam a geração de mais de uma página apresentam as maiores dificuldades desta classe de soluções.

2HTML - Hypertext Markup Language. (http://www.w3.org/pub/WWW/MarkUp/).
3FORM é um elemento (tag) da linguagem HTML que permite a definição de formulários em páginas HTML. Dentro de um formulário podem existir diferentes elementos HTML (INPUT, SELECT, A, etc) excepto novos elementos FORMs.
4URL - Uniform Resource Locator. (http://www.w3.org/pub/WWW/Addressing/).
5HTTP - Hypertext Transport Protocol. (http://www.w3.org/pub/WWW/Protocols/).
6POST e GET são dois dos métodos do protocolo HTTP amplamente suportados pelos servidores Web. GET permite invocar o pedido de um determinado documento na Web (em geral corresponde a um documento HTML). POST permite enviar o conteúdo dos campos de um elemento FORM para o servidor para ser tratado em geral por um processo CGI.
7MIME - Multipurpose Internet Mail Extensions. Definição geral de diferentes formatos/tipos de informação. Originalmente concebida para o serviço de correio electrónico, foi depois adoptado pelo protocolo HTTP. (http://www.oac.uci.edu/indiv/ehood/MIME/).
8Win-CGI - Robert Denny. Windows CGI 1.1 Description. (http://www.city.net/win-httpd/httpddoc/wincgi.html).
 Sistemas e Aplicações Hipermedia é uma coluna na net.News da responsabilidade de Alberto Silva, Investigador no INESC e Doutorando na área da concepção e construção de sistemas de informação hipermedia para a Web.
Sistemas e Aplicações Hipermedia é uma coluna na net.News da responsabilidade de Alberto Silva, Investigador no INESC e Doutorando na área da concepção e construção de sistemas de informação hipermedia para a Web.